
查看数据库类型
-- 划分
1.查询密集型 -- read
2.修改密集型 -- deleted,inserted,updated
-- 查询累计插入和返回数据条数
show global status like 'Innodb_rows%';
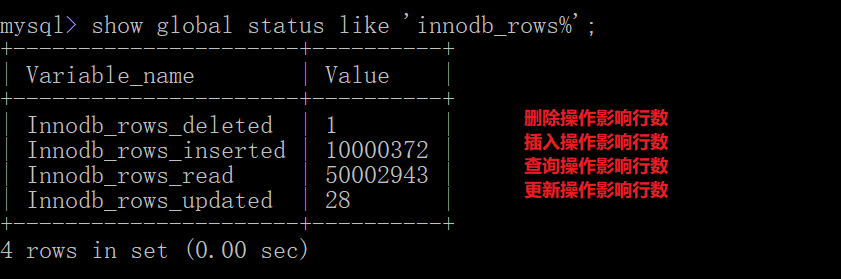
注意:
当查询修改比为8:2左右时,就可以使用索引来进行优化
索引
索引的作用
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。
索引分类
-- 主键索引
主键约束+提高查询效率
-- 唯一索引
唯一约束+提高查询效率
-- 普通索引
提高查询效率
-- 组合索引
多个字段组成索引,提高查询效率
-- 全文索引
solr,es
-- Hash索引
根据key-value效率高
创建索引
在已有表的字段上创建
-- 创建普通索引
create index 索引名 on 表名(字段);
-- 创建唯一索引
create unique index 索引名 on 表名(字段);
-- 创建普通组合索引
create index 索引名 on 表名(字段1,字段2,..);
-- 创建唯一组合索引
create unique index 索引名 on 表名(字段1,字段2,..);
在已有表的字段上修改
-- 添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
alter table 表名 add primary key(字段); --默认索引名:primary
-- 添加唯一索引(除了NULL外,NULL可能会出现多次)
alter table 表名 add unique(字段); -- 默认索引名:字段名
-- 添加普通索引,索引值可以出现多次。
alter table 表名 add index(字段); -- 默认索引名:字段名
创建表时指定
-- 创建学生表
CREATE TABLE student3(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键索引
name VARCHAR(32),
telephone VARCHAR(11) UNIQUE, -- 唯一索引
sex VARCHAR(5),
birthday DATE,
INDEX(name) -- 普通索引
);
查看索引
show index from 表名;
删除索引
-- 直接删除
drop index 索引名 on 表名;
-- 修改表时删除
alter table 表名 drop index 索引名;
查看是否使用索引
explain select 字段1,字段2,... from 表名;
参数说明
type:查询语句的性能
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
possible_keys:SQL查询时用的的索引key:SQL实际决定查询结果的键row:MySql查询时必须检查的行数
| 字段 | 含义 |
|---|---|
| id | select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。 |
| select_type | 表示SELECT的类型,常见的取值有SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION中的第二个或者后面的查询语句)、SUBQUERY(子查询中的第一个SELECT)等 |
| table | 输出结果集的表 |
| type | 表示表的连接类型 |
| possible_keys | 表示查询时,可能使用的索引 |
| key | 表示实际使用的索引 |
| key_len | 索引字段的长度 |
| rows | 扫描行的数量 |
| extra | 执行情况的说明和描述 |
索引的优缺点
-- 优点
提高数据检索的效率,降低数据库的IO成本。
索引底层就是排序,通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。
-- 缺点
需花费较多的时间去建立并维护索引。
需要占用一定的物理存储空间。
对表中的数据进行修改时,例如对其进行增加、删除或者是修改操作时,索引还需要进行动态的维护,这给数据库的维护速度带来了一定的麻烦。
索引创建原则
1.字段内容可识别度不能低于70%,字段内数据唯一值的个数不能低于70%。
2.经常使用where条件搜索的字段。
3.经常使用表连接的字段。
4.经常排序的字段。
索引的数据结构
B+Tree:优化BTree(非叶子节点:索引+指针、叶子节点:索引+数据【地址】)
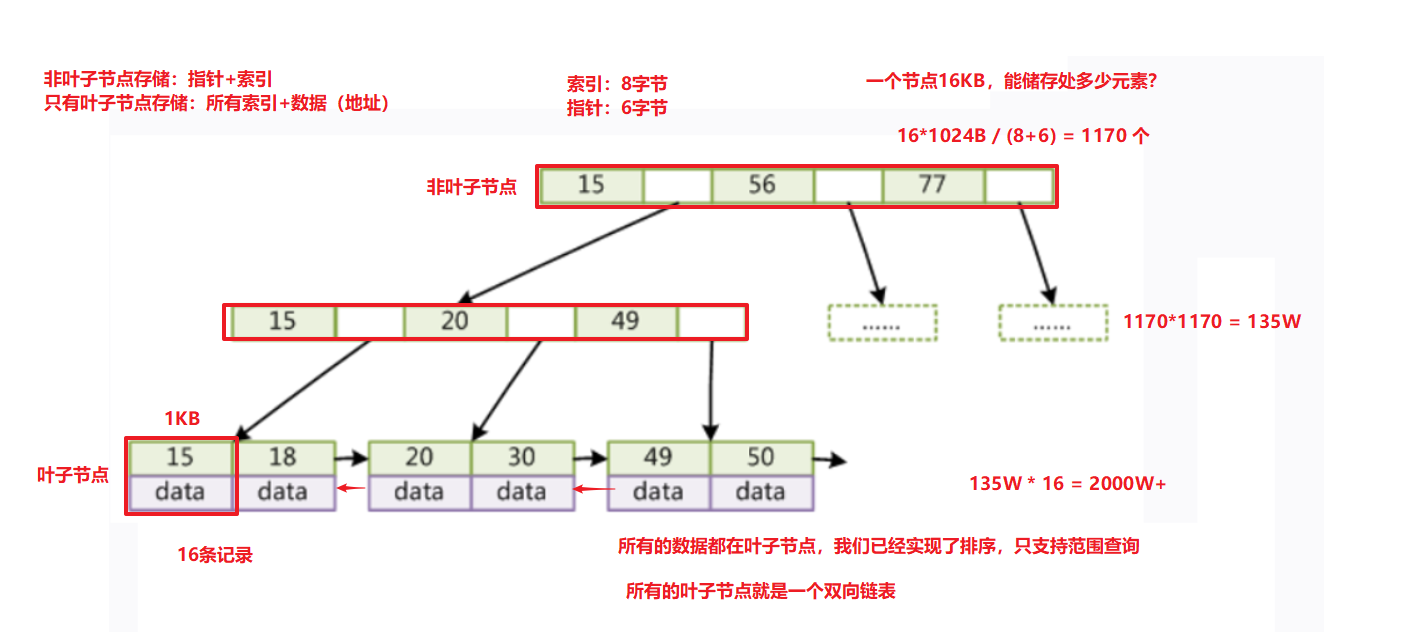
注意:
非叶子节点:存储索引+指针域
叶子节点:存储索引+数据或者数据的地址值
注意:
1)不同的存储引擎叶子节点存储的内容不一样
有可能是:索引+数据
也有可能是索引+数据的地址值
2)B+Tree是可以允许有冗余索引出现的,每个节点都有索引
注意:
一个索引占8字节,一个指针域占6字节,一个节点总共容量是16KB
一个节点可以存储的元素个数:
16*1024字节 / (8+6)=1170个元素
注意:
一次IO:读取1170个子节点
二次IO:读取1170*1170=135W个子节点
三次IO:读取135W*16=2000W+个元素数据
假设索引+数据域总大小是1KB。而每个节点一共能存储16KB。所以一个第三层一个节点大概可以存储16个元素即16条记录。
B+Tree的好处
- 降低树的高度
- 叶子节点按照索引排好序,支持范围查找,速度会很快
- 千万条数据,只有2次磁盘IO
查看索引节点
-- 查看mysql索引节点大小
show global status like 'innodb_page_size';